




On average, 500 million tweets are shared every day. This can be further broken down to 6,000 tweets per second, 350,000 tweets per minute, and around 200 billion tweets every year. 🤯
Despite the fact that each tweet is only 280 characters long, Twitter generates more than 12 terabytes of data per day. This is the equivalent of 84 terabytes each week and 4.3 petabytes per year. The tweets we send out every day generate a massive quantity of data.
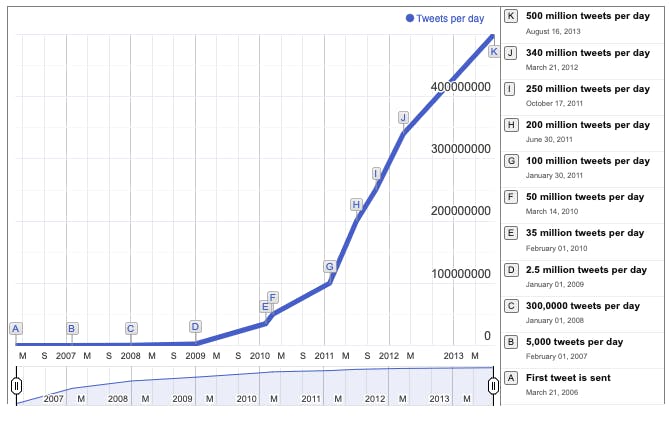
Earlier, Twitter used MySQL which was pretty fast and robust, and replication was easy. It used temporal sharding which is tweets from the same data range stored together on the same shard. The problem here was, that tweets end up filling one machine after another.
It was very expensive to set up a new cluster every few weeks. Additionally, they were facing issues with traffic since people are interested in what's happening now (the latest news).
While Linkedin was having a huge success with its in-house big data technologies like Kafka, Smasa, Voldemort & Espresso, none of Twitter's efforts were especially successful. 😮
Twitter build a brilliant data storage framework, Gizzard for creating datastores. A Gizzard is Twitter’s distributed data storage framework built on top of MySQL. 😄
Many modern websites require quick access to massive amounts of data that cannot be stored efficiently on a single computer. A good approach to cope with this issue is to "shard" the data, which means storing it on numerous computers rather than just one. Partitioning and replication are frequently used in sharding solutions. Partitioning divides data into small bits and distributes it across multiple computers. Multiple copies of the data are saved across multiple machines using the replication approach. The system can efficiently answer to a large number of questions because each replica operates on its own machine and can react to queries.
What is Gizzard ?
- Gizzard is a networking middleware service that manages data splitting across arbitrary backend datastores.
- The partitioning rules are stored in a forwarding table that maps key ranges to partitions.
- Declarative replication tree is used by each division to handle its own replication.
- Whenever we tweet, it's stored in an internal system "T-bird" which is built on the top of Gizzard. Secondary indexes are stored in "T-flock" (Gizzard-based) Unique Ids are generated using "Snowflake". FlockDB is used for ID to ID mapping. It basically stores the relationships between IDs.
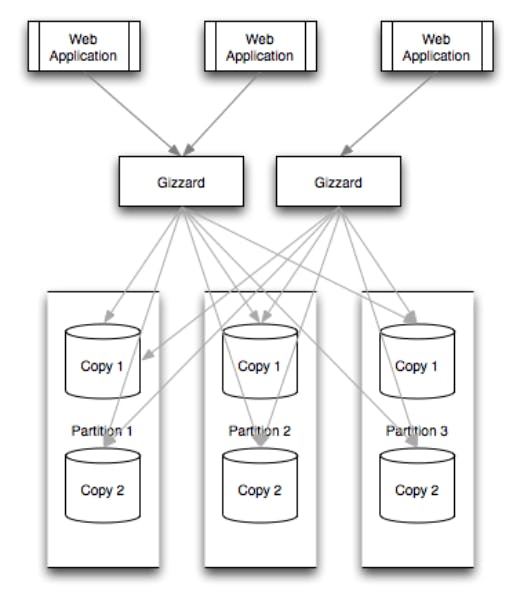
How replication and partitioning are handled by gizzard ?
1) Replication is handled using replication tree
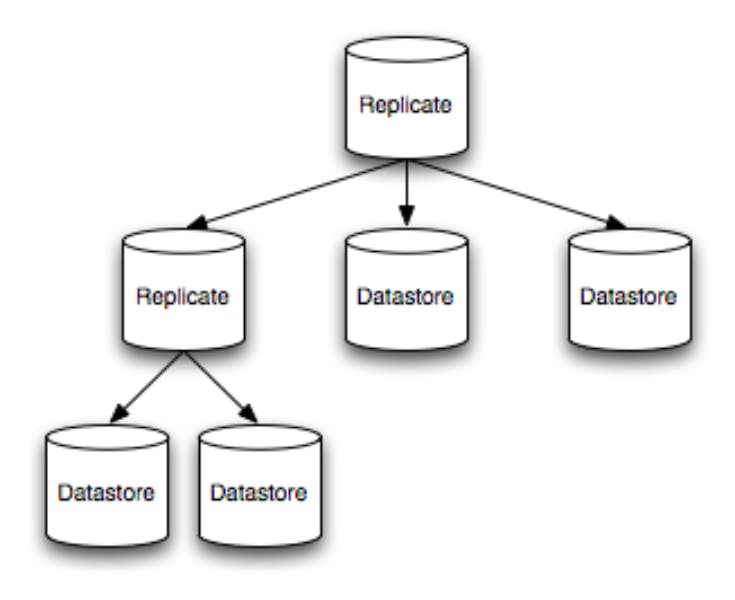
A physical or logical shard can be mentioned in the forwarding table for each shard. A physical shard denotes a specific data storage back-end, such as a SQL database. A logical shard, on the other hand, is simply a tree of other shards, with each branch representing a logical transformation of the data and each node representing a data storage back-end. These logical changes at the branch level are usually rules for propagating read and write operations to the branch's descendants.
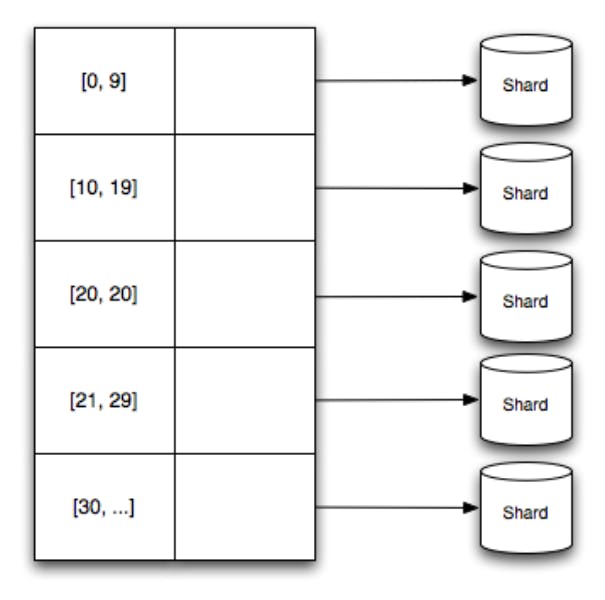
2) Partitioning is handled using forwarding table
Gizzard handles partitioning by mapping data ranges to specific shards. These mappings are kept in a forwarding table, which describes the lower bound of a numerical range as well as the shard to which the data in that range belongs.
A custom hashing function is given, providing a key for your data that produces a number that belongs to one of the ranges in the forwarding table. This approach differs from consistent hashing.
Advantages:
1) Fault-tolerant, it is designed in such a way that it avoids single point failure.
2) Migrating data becomes easier, which helps to deal with hardware failure.
3) It is designed to replicate data across any networks available, this could be relational databases, Lucene, Redis, or anything you can imagine.
References:
[1] blog.twitter.com/engineering/en_us/a/2010/i..
[2] highscalability.com/blog/2011/12/19/how-twi..
[3] adweek.com/performance-marketing/twitter-op..