




If we go back to 2013, Linkedin had an email-based messaging system rather than a chat-based system. It was a monolith system, running in a single data center with "One Big Database" 🤯
As LinkedIn grew and started developing new features, the complexity of the system began to snowball, slowing down the developer experience and speed. What used to take a week to implement started taking a month. 😮
Over time Linkedin added new data centers and switched to distributed data storage with shared architecture using its own NoSQL database. All of this led to one of the first major changes to the email-based messaging system. But, The move was long and fraught, and the resulting architecture introduced new challenges.
The next major change in the product came in 2016, LinkedIn continued to add functionality, eventually renaming the service Messaging. However, it was still based on a data architecture meant for email-style exchanges between two people, with a ten-year-old codebase, making it difficult to partition the data effectively for scaling.
Motivation
- The backend was built as a monolith with no clear separation between data-access and business-logic layers.
- A large amount of legacy code accumulated.
- Over the years, engineers from partner teams contributed elements of business logic that the core team lacked context for.
Old System
In the former system, every persistence-based messaging program or web-based application that supports read/write in general had a simple representation.
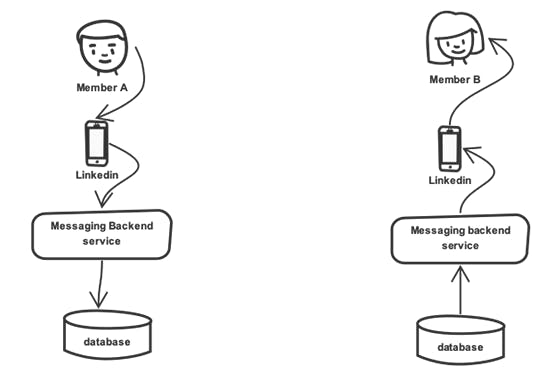
As you can see in the diagram above, when member A sends a message to member B, it passes through a backend service before being stored in the database. Member B then uses the service's read API to read the message.
In the database, engineers had an option to normalize the data or just store it in a normalized form. In the old system, they used to store data in denormalized form. However, this approach soon became costly with a lot of duplication. Additionally, providing features, like editing and deleting messages, with low latency was almost impossible.
The migration was divided into 3 phases:
Phase 1: The dual-write: Online Replication
The main objective of this phase is every write and update operation by the users must be replicated in real-time. The replication is very robust and completely transparent to the sender and recipient. This method is asynchronous dual-write.
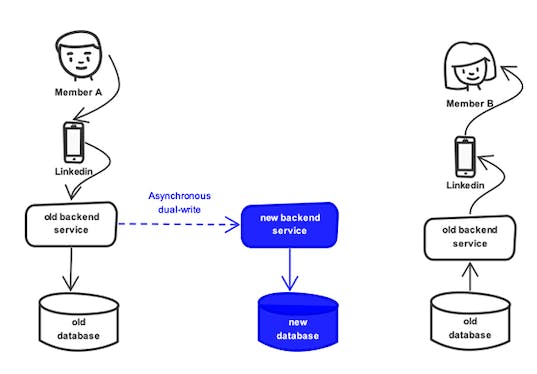
Phase 2: ID generation and mapping
In order to store the ID of the message in the new system, a new field was added to the database of the old system as part of phase 2. For each communication, they created synthetic new-system IDs and filled in this field. Every message in the old system corresponds to a new-system discussion ID and message ID.
As the name implies, the conversation ID identifies which conversation a message belongs to. Linkedin picked UUIDs to generate discussion IDs since they can be used in both offline and online systems.
Phase 3: Transform and bulk upload
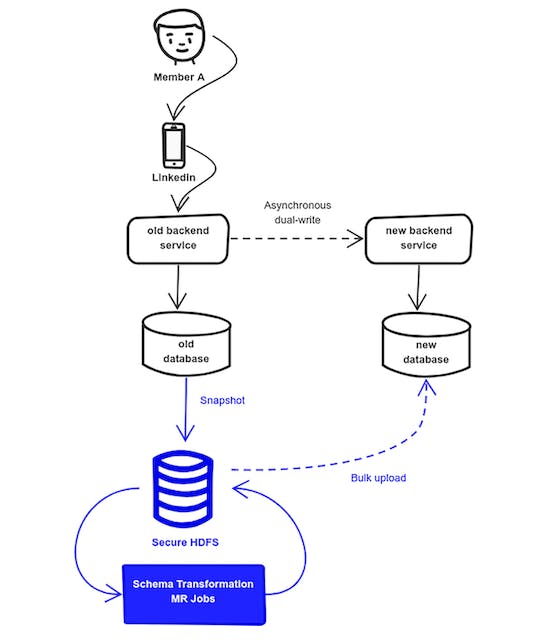
As you can see once all the IDs were in place, a snapshot of the old database was ETLed to a secure Hadoop cluster. A series of Map-Reduce jobs were performed and bulk uploaded to the new system database.
Once all the records were uploaded to the new system, it was very necessary to verify that members would be able to continue viewing and interested in their mailbox as they did in the old system. A shadow verification system was developed.
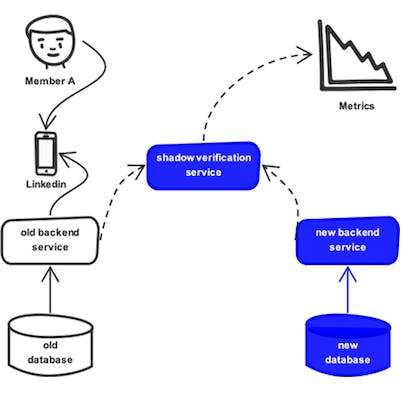
The message is served via old-system backend services and databases when member B opens a message on LinkedIn. The above-mentioned shadow verification service starts an asynchronous operation that reads the identical message from the new-system backend service. Both backends' messages are normalized to the same client models and iteratively compared field by field.
Conclusion
There were certainly a lot of iterations, making it scalable. But, this data migration was one of the successful breakthrough in how we use LinkedIn today. The enormous effort and meticulous preparation behind a phased approach, the parallel nature of the design, and the patience to do it well were all key to its initial success.
References:
[1] engineering.linkedin.com/blog/2020/designin..